
Upgrading the performance of Signia AX with Auto EchoShield and Own Voice Processing 2.0
Niels Søgaard Jensen, Claudia Pischel, Brian Taylor
Introduction
Signia AX, introduced in 2021, is a significant departure from traditional signal processing found in other hearing aids, and it addresses the most common problem associated with hearing aid use: performance in background noise (Picou, 2020). As a world’s first, the groundbreaking Augmented Focus technology includes split processing in which Signia’s unique beamforming technology is used to split speech and background noise into two separate streams, a focus stream and a surrounding stream, allowing completely separate processing of each stream (Branda, 2021). The result is that, unlike traditional hearing aid processing, speech is processed optimally without being affected by the background noise. Likewise, the noise signal is processed independently from the speech; thus, background noise remains audible and contributes to the perception of the soundscape, but speech continues to remain audible to the wearer.
Signia AX wearer benefits have been demonstrated in several studies. Improvements in speech intelligibility in background noise have been shown both in lab experiments simulating restaurant and party scenarios (Jensen et al., 2021a)-where theparticipants’ performance in the latter scenario even surpassed that of a normal hearing control group and inobjective speech tests performed in participants’ own homes (Jensen et al., 2021b). These results are consistent with survey data from new AX wearers in which 81% of respondents reported to be satisfied with speech intelligibility in real world listening, compared to only 43% who were satisfied with the speech intelligibility offered by their own, previously fitted hearing aids (Jensen et al., 2021c). This survey of real-world listening also showed Signia AX provided clear improvements (reductions) in perceived listening effort, and additionally, respondents felt more energized and more confident when wearing AX.
Given the possibilities of the robust AX platform, new signal processing features have been added to Signia AX. Two new features allow wearers to optimize performance in specific communication situations. One, Auto fchoShie/dautomatically scans the environment and adjusts processing according to the acoustics of the room, reducing the detrimental effects of reverberation, thereby improving speech clarity. Two, Own Voice Processing 2.0further improves Signia’s already proven Own Voice Processing (OVP) functionality by enabling separate processing of the wearer’s own voice and surrounding sounds, providing a more stable sound picture and a better perception of own voice when the wearer speaks.
In this white paper we present the outcome of a study performed at Horzentrum Oldenburg in Germany where the perceptual effects of these two new features were assessed. However, before describing the details of the study and its results, we will briefly explain the features.
Introducing the new AX features
Auto EchoShield
The Auto EchoShield feature addresses the situation where the wearer is present in a room with reverberation caused by multiple sound reflections (echoes) from the room surfaces. Figure l illustrates this reverberant situation. It shows different types of sound paths from the sound source to the listener. Besides the direct sound (shown in red), both early reflections (shown in blue) and later reflections (where the sound may have been reflected multiple times by different surfaces) reach the listener. When the sound is speech, the direct sound and early reflections both contribute positively to speech intelligibility at the position of the listener, whereas the later reflections may have a deteriorating effect, and may be so intense they cause temporal and spectral smearing that distorts the speech (e.g. Kuttruff, 2009). The more reverberant the room, for example as measured by the reverberation time (T60), the more dominant the later reflections will be, and the more likely speech intelligibility will be degraded.
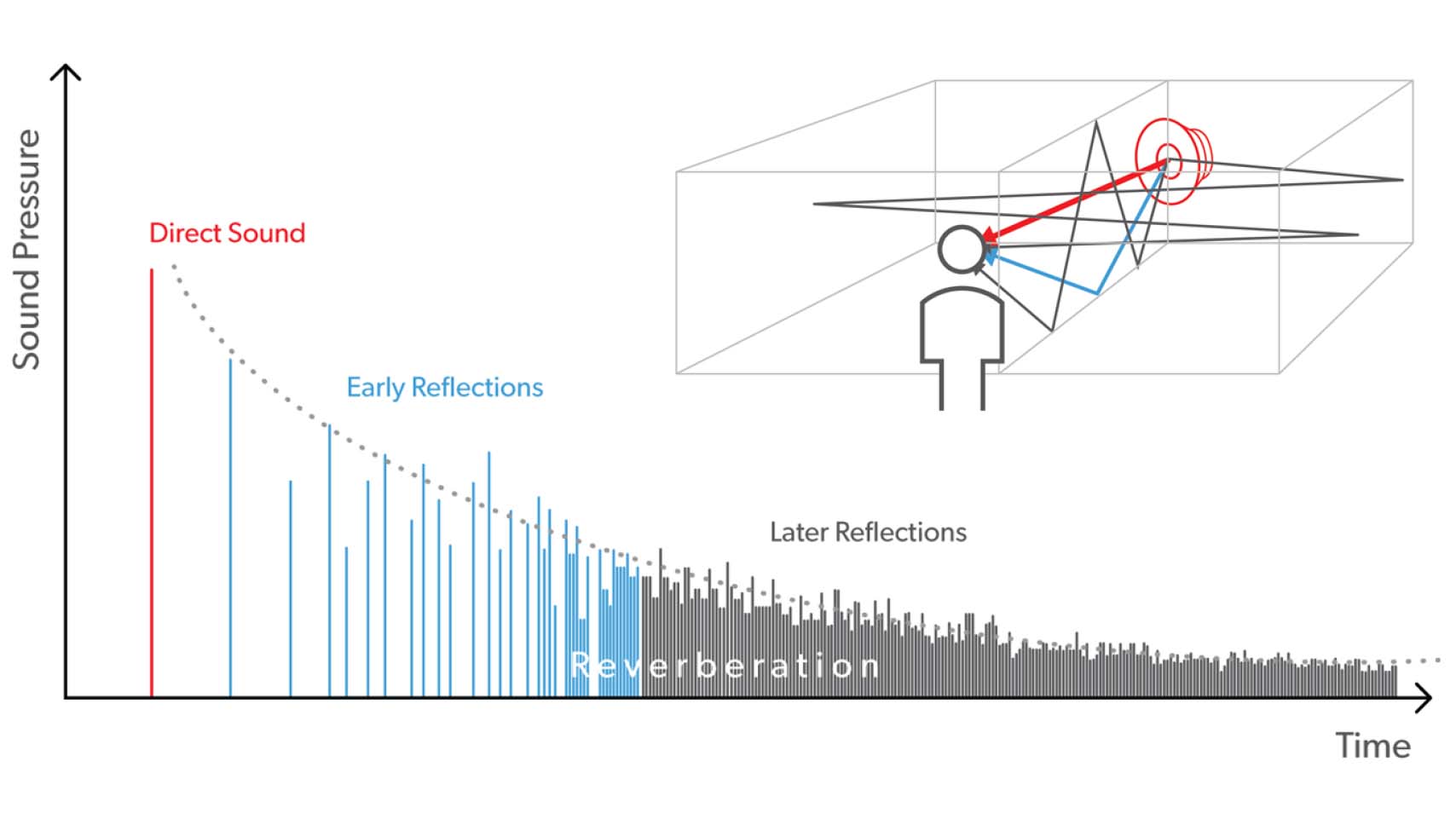

Figure 1. Illustration of direct sound, early reflections and later reflections when an impulse sound is transmitted to a listener in a room with reverberation.
The problems caused by reverberation are experienced by all listeners, regardless of hearing status. For hearing aid wearers, however, problems in reverberant conditions often are worse due to the non-linear gain of their hearing aids. Because gain is greater for lower (softer) inputs, late reflections may be overamplified and create additional problems for the wearer when listening to speech in reverberant conditions.
Auto EchoShield addresses the problem by constantly monitoring the surroundings. When a sound signal is present in a room, an advanced algorithm is used to estimate the slope of the reverberation tail and thereby the reverberation time. The system constantly performs an analysis that provides the best processing to maintain, but not overamplify, the room acoustics and to ensure good speech clarity. Thus, when the later reflections are likely to cause deteriorations of speech, the processing is adjusted to reduce the later reflections while the gain of the direct sound and the important early reflections is maintained. This is illustrated in Figure 2, which shows the effect of turning Auto EchoShield on in a reverberant room when a short impulse sound is present in the room. The plot shows the acoustic output of the hearing aid as a function of time, with and without Auto EchoShield. Figure 2 clearly shows how the early reflections, which are present in the first approximately 50 ms of the signal, are preserved, while the later reflections are substantially reduced by Auto EchoShield. In the case of a speech signal, less interference with speech cues that follow would occur, resulting in improved speech clarity and less effortful listening, and without losing the timbre or color of the room – an important listening characteristic provided by the early reflections.
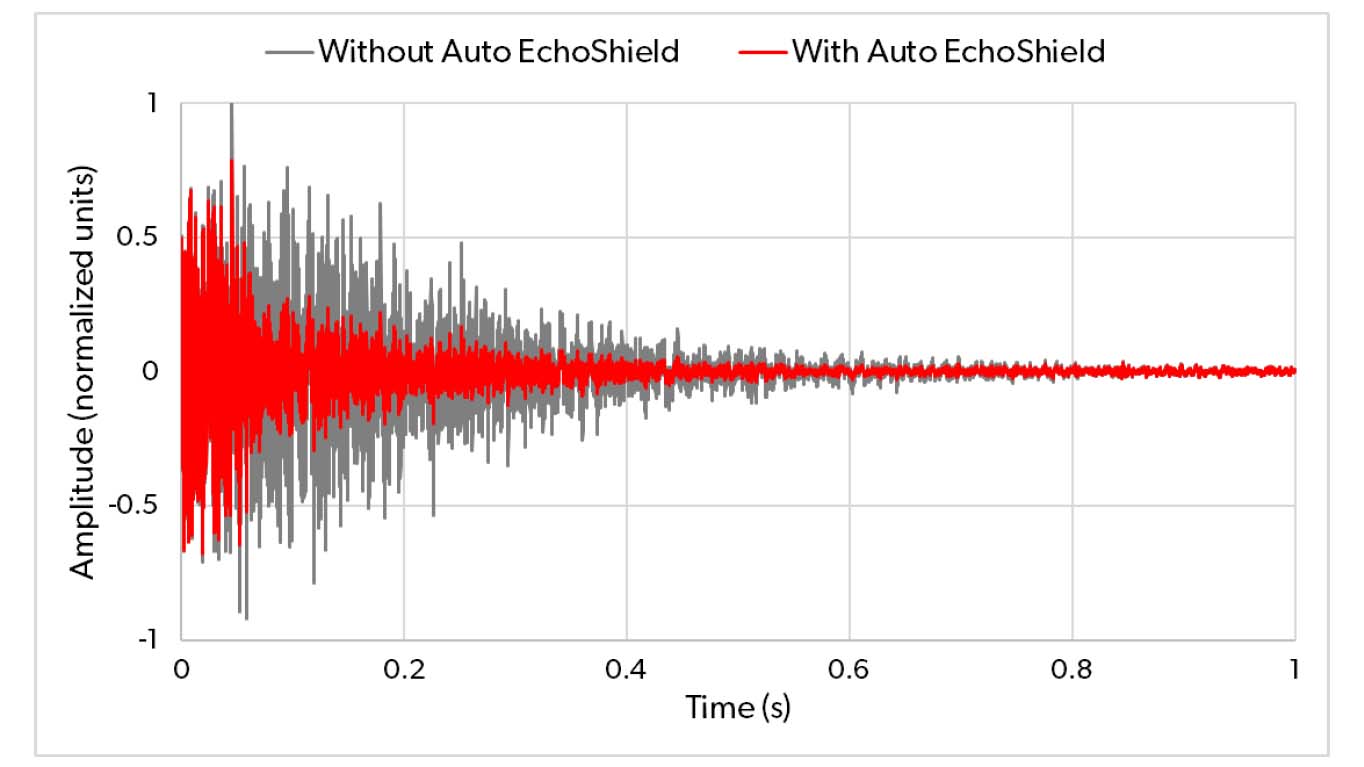

Figure 2. Recordings of an impulse sound, made in the ear of KEMAR fitted with Signia AX. The gray signal is recorded with Auto EchoShield turned off, while the red signal is recorded with Auto EchoShield turned on.
As the name indicates, the Auto EchoShield feature builds on some of the principles of the existing EchoShield program. However, as opposed to the manually selected program, which only includes one setting of the processing, Auto EchoShield automatically scans the environments and activates when needed. It adjusts its processing to the detected amount of reverberation in the room where the wearer is present. Thus, Auto EchoShield constantly optimizes the processing to the acoustic surroundings, regardless of whether it is low or high amounts of reverberation.
Own Voice Processing 2.0
Since its introduction, Own Voice Processing (OVP) has been a unique technology only offered by Signia. While the underlying signal processing is advanced, the overall concept and method of use is simple. When a quick and simple OVP training procedure has been completed as part of the initial fitting, the hearing aids are able to detect when the wearer speaks and adjust gain to accommodate for the changed acoustic conditions present when the wearer listens to their own voice, as compared to listening to external sounds. Previous studies indicate both high levels of satisfaction and strong preferences for OVP (H0ydal, 2017; Powers et al., 2018a; Powers et al., 2018b; Froehlich et al., 2018).
In Signia AX, the Own Voice Processing has been upgraded to version 2.0. This upgrade stems from split processing, the signature feature of the AX platform. It utilizes the fact that the wearer’s own voice is mainly present in the front hemisphere. With Own Voice Processing 2.0 and the use of split processing, it is now possible to pick up and optimize the sound of the wearer’s own voice independently from the surrounding sounds which are processed in another stream, as illustrated in Figure 3. This allows for an even more pleasant and stable sound of both own voice and surroundings.
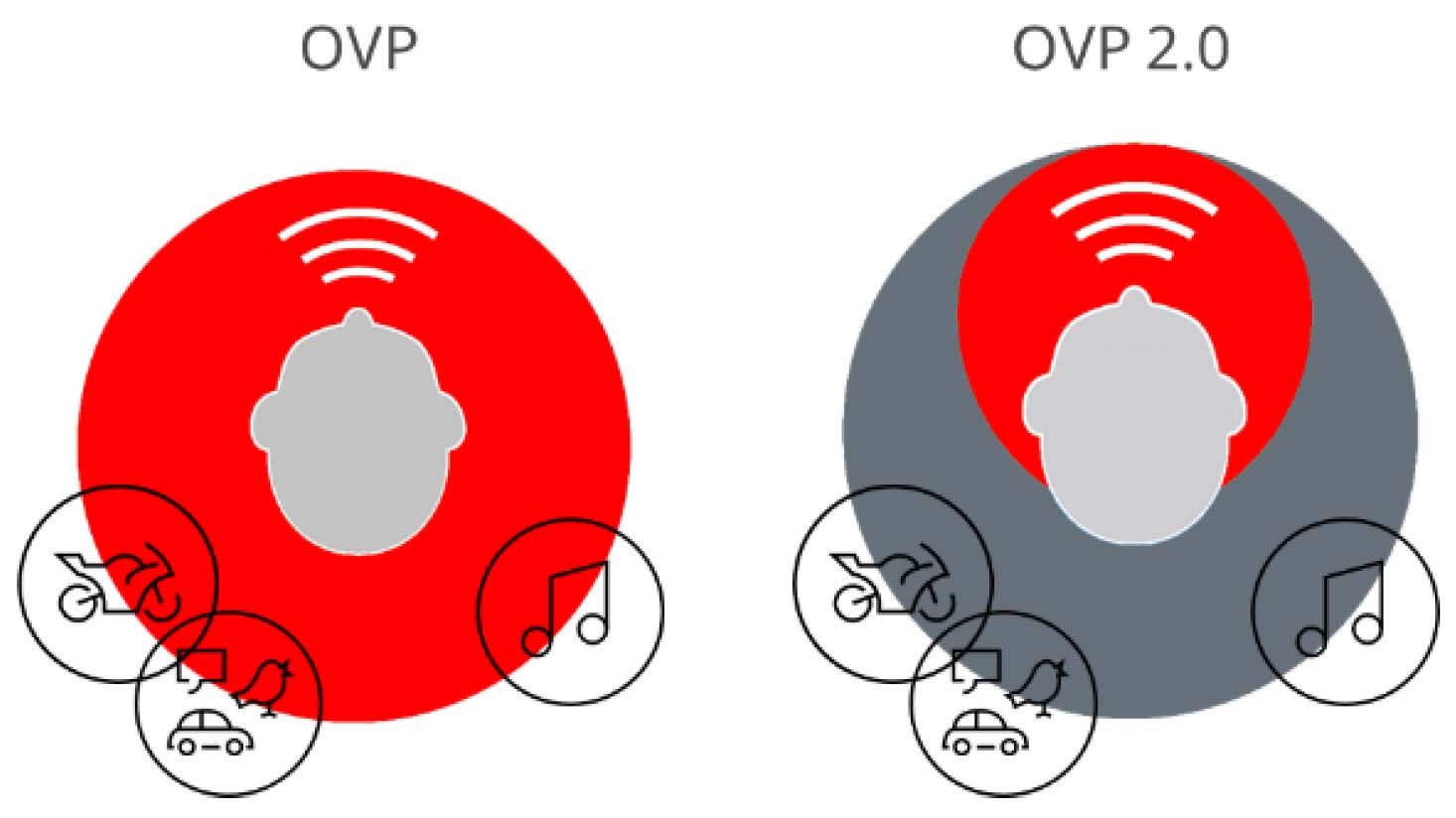

Figure 3. Left: Own Voice Processing where the wearer’s own voice and surrounding sounds are processed in the same way. Right: Own Voice Processing 2. 0 with separate processing of own voice and background sounds, allowing optimal and stable processing of both.
Testing in the lab
To evaluate the perceptual effects of Auto EchoShield, a listening test was conducted in the lab of Horzentrum Oldenburg where participants listened to recordings made in highly reverberant conditions with different types of hearing aid processing schemes.
Method (lab)
26 people (13 female, 13 male) with a mild-moderate sensorineural hearing loss were recruited to participate in the study. Their average age was 73.3 years (range 58-82 years), and they were all experienced hearing aid wearers. The average audiogram for the left and right ears of the participants is shown in Figure 4. The participants were required to have an audiogram with a slope close to the slope of the standard N2 audiogram (Bisgaard et al., 2010), in order to allow them to listen to and evaluate the same set of recordings, based on the same target audiogram, but with an individual gain adjustment applied.
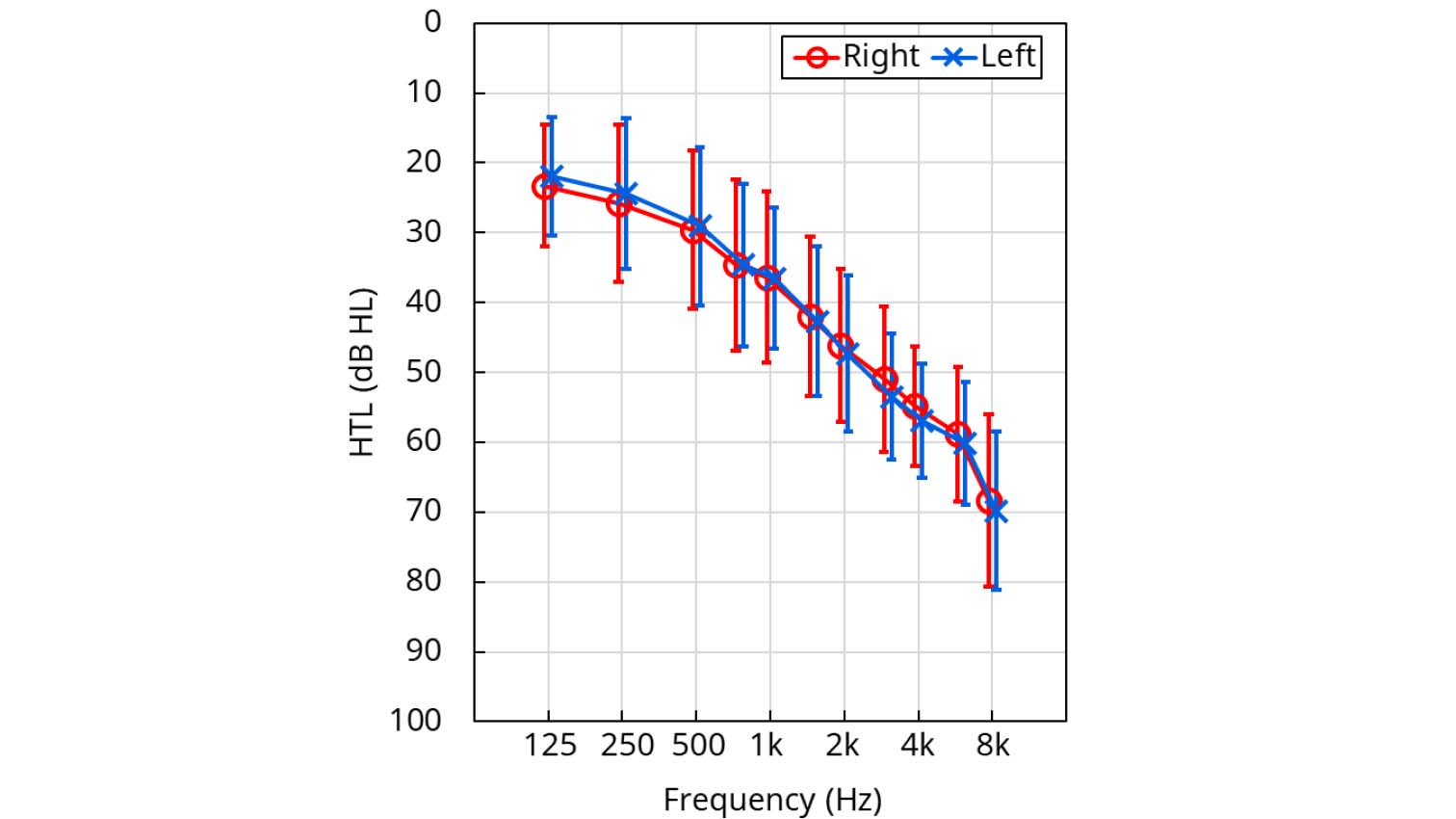

Figure 4. Mean audiogram for left and right ears of the 26 participants. The error bars show± one standard deviation.
Participants listened to recordings made in a simulated church scene, realized in a lab setup with 5 loudspeakers. The sound scene was a sample from a priest’s sermon in a large church with a reverberation time of approximately 3.5 secs. The voice of the priest was the only sound source in the scene. The recordings were made in the ears of a KEMAR manikin fitted bilaterally using closed ear tips with three different sets of test hearing aids:
- Signia AX with Auto EchoShield, programmed to the target audiogram using the AX First Fit rationale.
- A traditional hearing aid setting, implemented on the AX platform, without Augmented Focus, programmed to the target audiogram using the NAL-NL2 gain rationale with fast compression.
- Hearing aids from a main competitor (Brand A), programmed to the target audiogram using the manufacturer’s proprietary rationale and with all adaptive processing enabled.
The sound stimulus was on for 45 secs before each recording was started to allow all the hearing aids to adapt to the scene. After the recording, the three recordings were loudness equalized, and they were cut and time-aligned to enable direct cross-fade during the assessment procedure. The duration of the recordings was around 20 secs, and the recordings were played in a loop during assessment.
In the lab assessment, the participants listened to the recordings via a pair of Sennheiser HD 650 headphones. Before the actual assessment, each subject adjusted the overall volume to their own preference, and this volume setting was then kept constant.
The participant’s task was to rate the perceived reverberation and the speech clarity on a scale from Oto 100 with each of the three hearing aids. Please note that for reverberation, a high rating is bad, while for speech clarity, a high rating is good. In the assessment of a given sound attribute (reverberation or speech clarity), the subject was able to switch freely between the three hearing aids, and the rating was made by positioning a slider on a screen in front of the participant. When the three ratings of one attribute were completed, a switch was made to the other attribute. The order of attributes was counterbalanced across participants.
Results (lab)
The results of the headphone listening test are summarized in Figure 5. The left plot shows the mean ratings of perceived reverberation for the three test hearing aids where a high rating indicates a high level of reverberation. The plot shows a striking difference between Signia AX and the two other conditions, with the reverberation perceived with AX being rated around 20 scale points lower on the 100-point scale than the two other conditions. Both differences were statistically significant (p < .01) according to a
Wilcoxon matched pairs test.
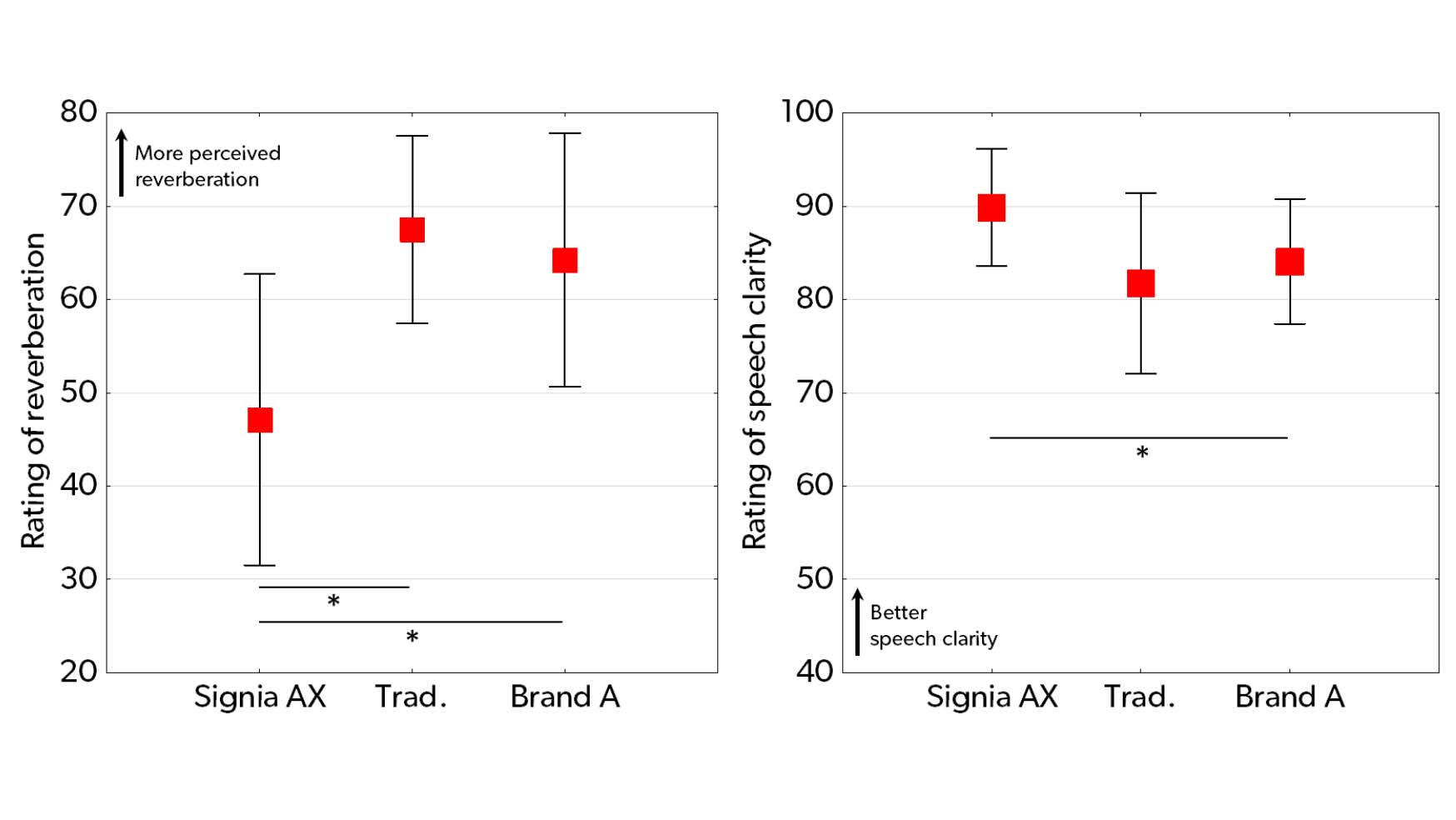

Figure 5. Mean rating of reverberation (left plot) and speech clarity (right plot) for each of the three hearing aid conditions (Signia AX, Traditional processing, and Brand A). Error bars show 95% confidence intervals. Asterisks indicate statistically significant differences (p < .05).
The right plot in Figure 5 shows the mean ratings of speech clarity. The best speech clarity was provided by Signia AX where a mean rating of 90 on the 100-point scale was observed. While the mean ratings of the two other conditions also were in the higher end of the scale (82 and 84, respectively), they were both lower than the AX rating, which was l 0% and 7% higher than the mean ratings of the traditional setting and the competitor hearing aids, respectively. Even though the largest mean difference was observed in the comparison with the traditional setting, the large variation in the ratings of the traditional setting resulted in only the mean difference between AX and the competitor hearing aids being statistically significant (p < .05, Wilcoxon matched pairs test).
The observed mean ratings in the highly reverberant church scene clearly illustrates how the Auto EchoShield feature can substantially reduce the reverberant effect. This reduction in perceived reverberation is accompanied by an improvement of the perceived speech clarity, making it more comfortable and easier to follow what is being said. The additional benefits of reducing the perceived reverberation were further explored in the following real-life testing.
Testing in real world listening conditions
To assess the effects of Auto EchoShield in real world conditions, a guided walk was completed where participants were exposed to both reverberant and non-reverberant conditions. The real-life testing also included assessment of Own Voice Processing 2.0.
Method (real-world listening)
The real-life testing included 17 of the participants from the lab test. They were all fitted with Signia Pure Charge&Go AX RIC hearing aids, with Auto EchoShield and Own Voice Processing 2.0, using with closed couplings (power domes). The hearing aids were programmed to the individual audiogram using the AX First Fit rationale. During the fitting, Own Voice Processing 2.0 training was completed. Participants were encouraged to use the prescribed gain settings, but changes in the master gain were accepted if desired. Immediately after the fitting, a spontaneous acceptance test was completed where the participants answered several questions about the sound quality of their own voice as well as the sound quality of the experimenter’s voice. The questions were answered on a four-point rating scale. In the analysis of the participants’ ratings, questions were combined to address specific topics. For example, one mean rating of own voice loudness was obtained by averaging ratings of three own voice loudness-related questions. To ease interpretation, the mean ratings were transformed linearly to a 0-10 scale, with higher ratings indicating higher levels of satisfaction.
Using a special Matlab script on top of the Connexx fitting software, the traditional setting used in the lab test was implemented as a second program in the hearing aid. Thus, the setting was implemented on the AX platform, without Augmented Focus, Auto EchoShield and Own Voice Processing 2.0, and programmed to the individual audiogram using the NAL-NL2 gain rationale with fast compression. For this AX program, changes in master gain were also allowed if desired by the participant.
The two programs (AX and traditional processing) were assigned randomly to Program l and 2 in the test hearing aids, without informing the participants about the differences between the programs.
Following the fitting of the test hearing aids, a guided walk was completed in groups of three participants and two experimenters where the participants assessed and compared the two hearing aids in different real-life situations. For practical reasons, two participants did the guided walk alone (together with the experimenters). The fact that the study was conducted during the COVID-19 pandemic meant that several restrictions applied that affected which locations could be used, and how the participants could act in these locations.
The reverberant entrance hall of the Horzentrum test site was used to assess Auto EchoShield. However, due to the restrictions, the participants needed to wear facemasks, and only one of the experimenters was allowed to talk without wearing a facemask. This meant that we could not meaningfully assess Own Voice Processing 2.0 in this location, but only sound attributes related to the perception of the experimenter’s voice and its interaction with the room. The included attributes were speech clarity, perceived speech intelligibility, listening effort, room perception (the interaction between room and sound), listening comfort and overall satisfaction. The task of the participant was to switch between the two programs and, for each attribute, rate their preference on a visual analogue scale from -5 (program l much better) to +5 (program 2 much better).
To allow assessment of Own Voice Processing 2.0, the participants were taken into a garden just next to the test site. The garden is a rather quiet place with soft ambient noise, and with minimal reverberation. In this outdoor location the participants did not have to wear facemasks, and therefore were able to assess the sound quality of their own voice. Furthermore, the communication situation involving both the experimenters and the other participants was assessed in this location. The participants’ task was the same as in the entrance hall. For five different attributes, they rated their preference between the two hearing aid programs scale on a scale from -5 to +5. Compared to the entrance hall, an added attribute was the sound of own voice, while ratings of perceived speech intelligibility and listening comfort were left out in this less challenging situation.
Results (real-world listening)
The mean preference ratings for each of the six attributes assessed in the reverberant entrance hall are plotted in Figure 6. For all six attributes, a preference for Signia AX with Auto EchoShield over the traditional processing was observed. The mean benefits were in the range between l and 2 scale points, with mean ratings of speech intelligibility and overall satisfaction exceeding 2 scale points. All mean ratings were significantly higher than O (no difference), indicating significantly better performance of Signia AX, according to paired t-tests (all p < .05). Thus, the benefits of the AX platform, and in particular Auto EchoShield, were clearly perceived by the participants in this location. The mean preference ratings of speech clarity and perceived speech intelligibility were 1.8 and 2.1, respectively, which indicate a strong preference of the speech processing in Auto EchoShield.
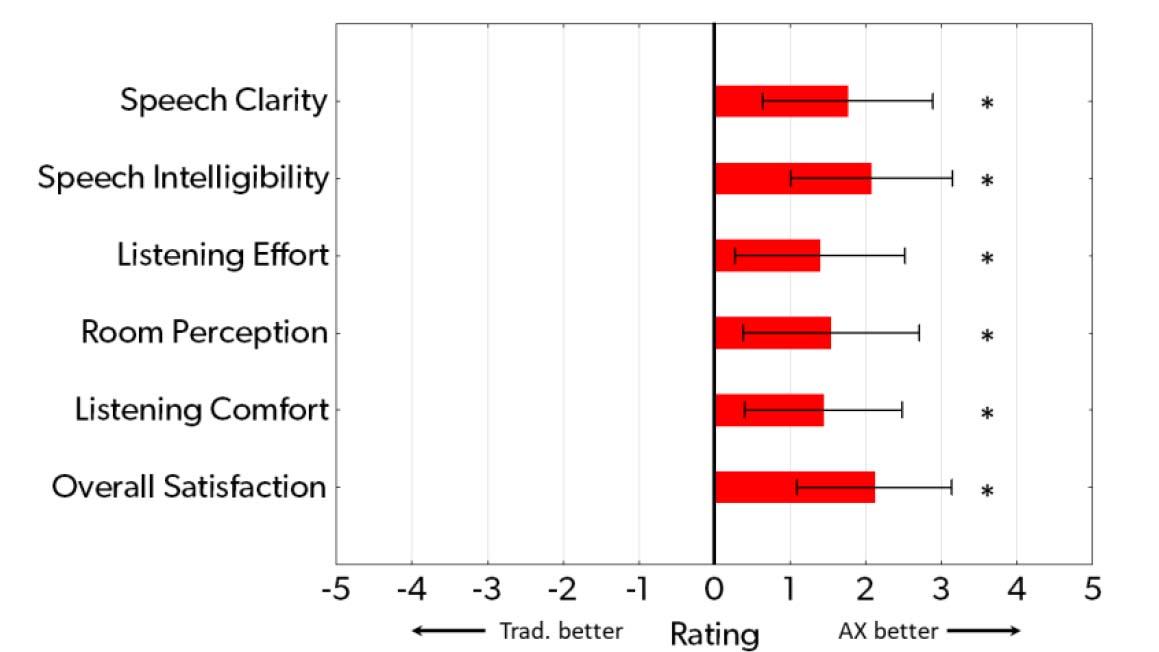

Figure 6. Mean ratings of the preference for Signia AX vs. traditional processing in six different outcome domains, assessed in a reverberant entrance hall. Positive ratings on the scale indicate better performance of Signia AX, while O indicates no difference. Error bars indicate 95% confidence intervals. Asterisks indicate a significant preference for one setting (p <. 05).
Figure 7 shows the mean ratings of the five attributes that were assessed in the outdoor location. Again, in this location, a preference for Signia AX over traditional processing was observed for all attributes. However, the magnitudes of the mean ratings (benefits) were generally lower than in the entrance hall, and for three of the attributes (listening effort, room perception, and overall satisfaction), the benefit was not statistically significant according to paired t-tests. However, for the two remaining attributes, speech clarity and own voice, a significant benefit was observed (p < .05).
The own voice benefit, seen as a mean preference rating of 1.6 scale points, relates directly to Own Voice Processing 2.0 which was available in the AX program, whereas the speech clarity benefit can be attributed to the entire AX processing, which is dedicated to the processing of speech in all types of room conditions – including the ‘extreme’ outdoor situation without reverberation.
The fact that the mean preference for AX with respect to room perception (the interaction between the sound and the surroundings) was smaller (0.9 scale points) and non significant is not that surprising in this type of outdoor environment. The same trend holds true for listening effort where a small and non-significant preference rating also was observed. Given the quiet environment and the rather easy communication situation, it was neither expected that a lot of listening effort would be required nor that one hearing aid could provide a substantial listening-effort benefit over another. In this environment, it was clearly the own-voice and speech-clarity benefits that were most dominant.
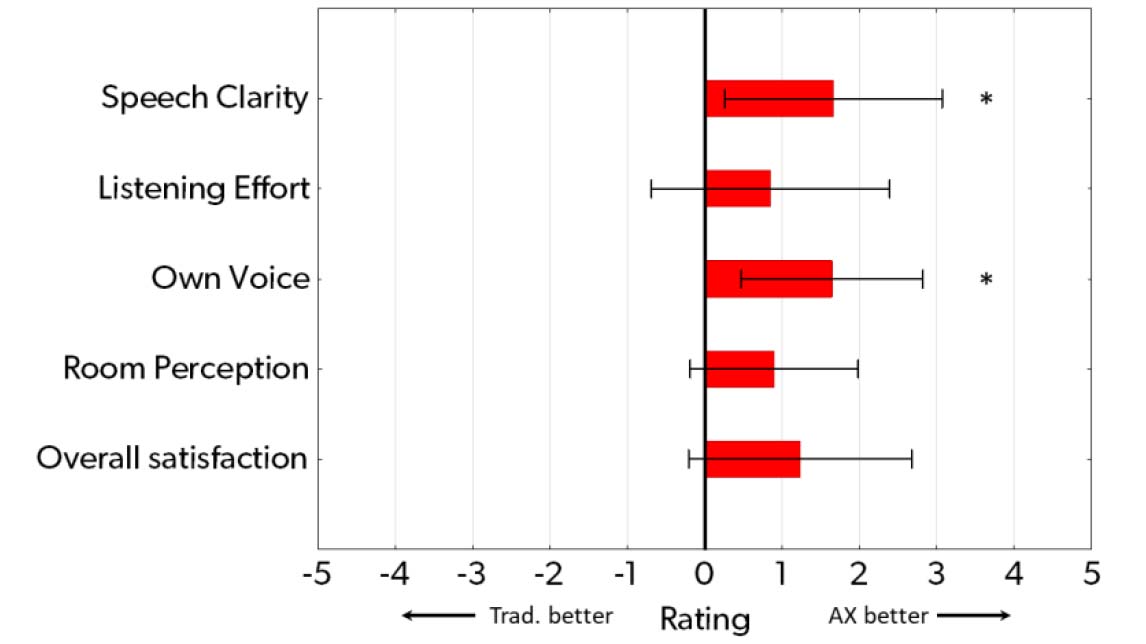

Figure 7. Mean ratings of the preference for Signia AX vs. traditional processing in five different outcome domains, assessed in an outdoor setting with no reverberation and with soft ambient noise. Positive ratings on the scale indicate better performance of Signia AX, while O indicates no difference. Error bars indicate 95% confidence intervals. Asterisks indicate a significant preference for one setting (p < .05).
In the spontaneous acceptance test, done just after the fitting of Signia AX (with closed fittings) and the completeion of the Own Voice Processing 2.0 training, the participants answered several questions on own voice, which were aggregated into two own voice domains: Loudness and sound quality.
The mean rating of own voice loudness across the 17 participants was 9.1 (on the 0-10 scale), while the mean rating of own voice sound quality was 8.2. When defining an individual rating above 5 as an indicator of satisfaction, all 17 participants (100%) were satisfied with the loudness of their own voice, while 15 participants (88%) were satisfied with the sound quality of their own voice when Own Voice Processing 2.0 was active, as displayed in Figure 8.
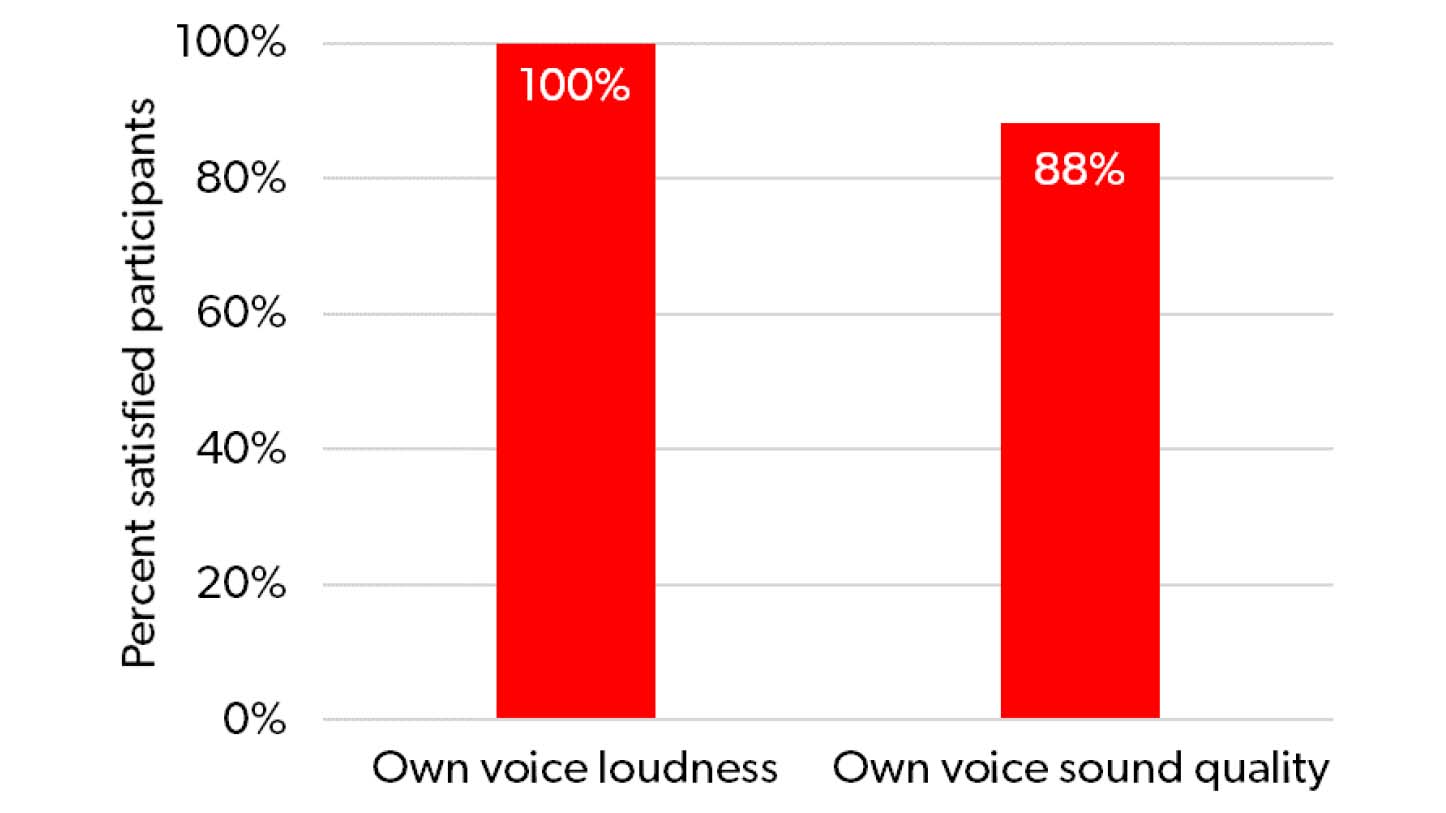

Figure 8. Percentage of participants who were satisfied with the loudness and the sound quality of their own voice, immediately after being fitted with Signia AX with Own Voice Processing 2.0. The fittings were done with closed power domes.
The participants also answered questions regarding the perception of the experimenter’s speech, i.e. speech in quiet. The answers were aggregated in three domains: Loudness, sound quality and speech intelligibility. The observed mean ratings of the three domains were 9.1, 9.0 and 9.7, respectively, with 76%, 88% and 94% of the individual ratings being above 8 on the 10-point scale. Thus, the ratings indicated an excellent first impression of the speech processing offered by Signia AX- in this case, with ratings conducted in a low-reverberant fitting room, obviously without the influence of the new features, Auto EchoShield and Own Voice Processing 2.0, but driven by the basic processing offered by the AX platform. These findings suggest that in a relatively common listening situation, listening to one person talking in a quiet place, Signia AX provides outstanding immediate self-reported benefit.
Discussion
The Auto EchoShield feature implemented in Signia AX was assessed both in the lab and in real-world listening. The lab results showed that the audible effects are strong, providing a significant reduction of the perceived reverberation in a church environment. Even though the speech clarity provided by the two other test hearing aids, to which Signia AX was compared, was rated quite highly by the participants, Signia AX with Auto EchoShield was able to further increase the perceived speech clarity to a remarkably high level.
The lab results were in agreement with the findings made in the real-world part of the study-the guided walk-where Signia AX was reported to provide clear benefits over traditional hearing aid processing when listening to speech in a reverberant entrance hall. The speech clarity benefit was accompanied by significant improvements in both perceived speech intelligibility, listening effort, listening comfort and room perception, thus offering a strong advantage in this challenging communication situation. These findings demonstrate the powerful combined effects of Auto EchoShield and the split processing offered by the Signia AX platform.
Although pandemic-related restrictions limited the types of real-world places that could be assessed (without wearing facemasks) during the guided walk, Signia AX with Own Voice Processing 2.0 demonstrated strong performance in an outdoor setting where the sound of own voice and the speech clarity (of other speakers) was significantly improved. These findings are consistent with the results from the spontaneous acceptance test, which showed a remarkably high level of satisfaction with loudness and sound quality of own voice and with speech in quiet immediately after the fitting of Signia AX, even with closed fittings.
Summary
The two new features, Auto EchoShield and Own Voice Processing 2.0, provide Signia AX wearers with exceptional benefit in challenging communication situations. One, in a highly reverberant simulated church scene, Auto EchoShield reduced the perceived reverberation and increased the speech clarity compared to both a main competitor and traditional hearing aid processing. Two, when tested in a reverberant real-world situation, Signia AX provided significant benefit along several dimensions of self-report, including speech clarity, perceived speech intelligibility, listening effort, listening comfort and room perception when compared to traditional hearing aid processing.
Finally, when assessing Own Voice Processing 2.0 immediately after the fitting, l 00% of participants were satisfied with the loudness of their own voice, while 88% expressed satisfaction with the sound quality of their own voice. This finding was consistent with the assessment made in an outdoor communication situation where the participants rated the sound of their own voice significantly better than the sound provided by traditional processing.
References
Bisgaard N., Vlaming M.S. & Dahlquist M. 2010. Standard audiograms for the IEC 60118- 15 measurement procedure. Trends in Amplification, 14(2), 113-120.
Branda E. 2021. Split-processing: A new technology for a new generation of hearing aid. Audiology Practices, 13(4), 36-41.
Froehlich M., Powers T.A., Branda E. & Weber J. 2018. Perception of Own Voice Wearing Hearing Aids: Why “Natural” is the New Normal. AudiologyOnline, Article 22822. Retrieved from www.audiologyonline.com.
H0ydal E.H. 2017. A New Own Voice Processing System for Optimizing Communication. Hearing Review, 24(11), 20-22.
Jensen N.S., H0ydal E.H., Branda E. & Weber J. 2021a. Augmenting speech recognition with a new split-processing paradigm. Hearing Review, 28(6), 24-27.
Jensen N.S., Pischel C., Taylor B. & Schulte M. 2021b. Performance of Signia AX in at home listening situations. Signia White Paper. Retrieved from www.signia-library.com.
Jensen N.S., Powers L., Haag S., Lantin P. & H0ydal E.H. 2021c. Enhancing Real-World Listening and Quality of Life with New Split-Processing Technology. AudiologyOnline, Article 27929. Retrieved from http://www.audiologyonline.com.
Kuttruff H. 2009. Room Acoustics. 5th ed. Abingdon, Oxon: Spon Press.
Picou E.M. 2020. MarkeTrak 10 (MTl0) Survey Results Demonstrate High Satisfaction with and Benefits from Hearing Aids. Seminars in Hearing, 41(1), 21-36.
Powers T., Froehlich M., Branda E. & Weber J. 2018a. Clinical Study Shows Significant Benefit of Own Voice Processing. Hearing Review, 25(2), 30-34.
Powers T.A., Davis B., Apel D. & Amlani A.M. 2018b. Own Voice Processing Has People Talking More. Hearing Review, 25(7), 42-45.