
Improving speech understanding with Signia AX and Augmented Focus™
Niels Søgaard Jensen, Erik Harry Høydal, Eric Branda, Jennifer Weber
Introduction
In recent years, continued advancements in hearing aids have been made to improve the signal-to-noise ratio (SNR) and ease of listening for the wearer. We now have signal classification systems that can correctly identify multiple listening conditions, adaptive directional polar plots that can track a noise source (and reduce it), or automatically find a desired speech source (and enhance it), e.g. Ricketts et al., 2005; Chalupper et al., 2011; Mueller et al., 2011. Hearing aid signal processing has progressed to the point that for some listening-in-noise conditions, speech understanding for individuals with hearing loss is equal to or better than their peers with normal hearing (Powers & Fröhlich, 2014; Froehlich et al., 2015; Froehlich & Powers, 2015). Despite these advancements, the problem of not being able to understand speech in background noise is still one of the most dominant complaints made by hearing aid wearers (Picou, 2020).
Signia AX and Augmented Focus™
The speech-in-noise problem has been addressed by the Signia Augmented Xperience (AX) platform with its introduction of a new and innovative signal processing paradigm termed Augmented Focus™. See Best et al. (2021) for a detailed review of this new processing approach. In brief, the idea is to process the sound the wearer wants to focus on, typically speech, completely separately from the surrounding sounds. This split processing increases the contrast between focus and surroundings and makes the speech stand out as being clearer and easier to understand.
This new type of processing is enabled by Signia’s beamformer technology, which is used to split the incoming sound into two separate signal streams (see Figure 1). One stream contains sounds coming from the front of the wearer, while the other stream contains sounds arriving from the back. Both streams are then processed independently. This means that for each stream, a dedicated processor can be used to analyze the characteristics of the incoming signal from every direction and process the sound in 48 channels. If the signal contains information the wearer wants to hear, it will be processed as a Focus stream, whereas if it contains unwanted or distracting sounds, it will be processed separately as a Surrounding stream.
The separate processing of the two streams means the processing of both streams can be optimized without affecting each other. For example, compared to conventional single-stream processing, a speech signal can be processed with more linear gain, while more effective compression and noise reduction can be applied to a surrounding noise signal, without compromising the speech processing. The resulting effect is a sophisticated directional amplification pattern that augments the speech when the two streams are recombined in an intelligent mixing unit, which takes the information provided by the advanced Dynamic Soundscape Processing analysis (Froehlich et al., 2019) into account.
To enable wearers to hear desired sounds, the Focus stream is prioritized in the signal processing mix. By processing sounds in the Focus stream in a more linear manner, Augmented Focus creates a remarkable contrast to the more attenuated and compressed Surrounding stream. This results in the Focus sound being perceived by the wearer as being closer than the Surrounding sound, therefore, augmenting reality, and benefiting the wearer. The mixing of the streams also will depend on the SNR, the acoustic situation that is detected, and whether the wearer speaks and moves while listening. In demanding noisy listening situations, the mixing unit also can activate binaural beamforming in the front stream.
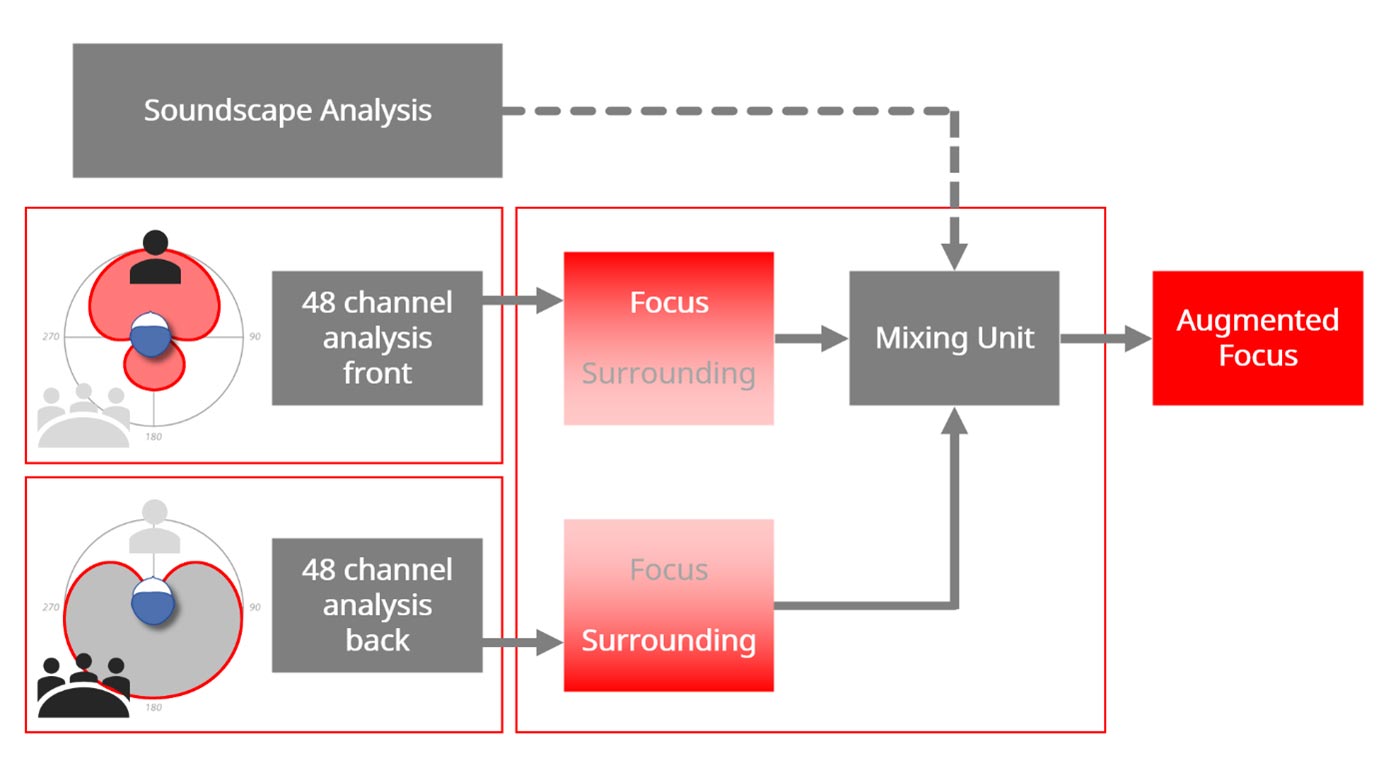
Figure 1. Schematic illustration of the split processing of the Signia AX with Augmented Focus. In this example, the speech coming from the front is detected and processed as a Focus stream, while the noise from behind is detected and processed as a Surrounding stream.
In addition to the SNR benefits, which improve speech clarity and understanding, Augmented Focus also enhances the wearer’s perception of background sounds by providing a fast and precise adjustment of the gain for surrounding sounds. This improves the stability of the background sounds, and consequently, the wearer’s perception of the entire soundscape is enhanced.
As previously stated, one of the expected advantages of Signia AX is improved speech understanding in dynamic listening situations; situations where there may be one or two primary communication partners, with random noise originating from unexpected locations. The present investigation simulated these listening environments and compared speech recognition measures in background noise for the following experimental design: Signia AX Augmented Focus “On” vs. “Off,” Signia AX vs. competitive devices, and Signia AX vs. individuals with normal hearing.
Methods
Participants
A total of 25 participants, divided into two groups, were included in this research. One group had bilateral hearing loss (HL), the other had normal hearing (NH).
HL Group: Sixteen adults (12 males, 4 females) were included in this group. Participant ages ranged from 21-83 years with an average age of 61.8 years; all were experienced wearers of bilateral amplification. All had symmetrical downward sloping sensorineural hearing losses. The mean audiogram is shown in Figure 2. All testing was conducted with the participants aided bilaterally.
NH Group: This group consisted of 9 individuals, 4 males and 5 females. The age range was 30 to 67 years, with an average age of 55.6 years. All participants had audiometric thresholds of up to 25 dB HL for the frequencies 250 to 4000 Hz. One case with a 30 dB dip in one ear at 4000 Hz was accepted. All testing was done unaided for the participants in this group.
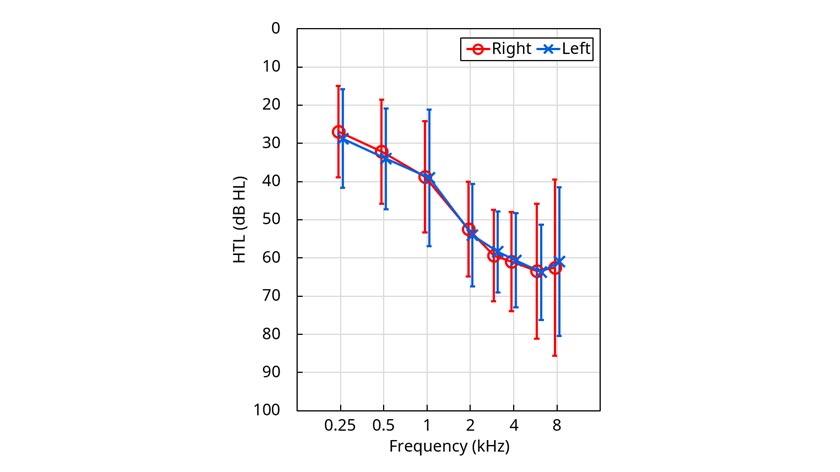
Figure 2. Mean right and left audiogram for the 16 participants in the HL group. Error bars show ± one standard deviation.
Hearing Aids
The hearing aids used in the study were the Signia Pure Charge&Go AX, and premium RIC devices from Brand A and Brand B, all programmed using the corresponding current software (April, 2021), with all features set to the default setting for the universal program (frequency-lowering was disabled for all products). The hearing aids were fitted with each manufacturer’s recommended most closed instant-fitting eartip. For each participant, all instruments were programmed to the NAL-NL2 prescriptive algorithm (experienced wearer, bilateral fitting), verified with probe-microphone measurements within +/-5 dB of prescriptive targets from 500 to 4000 Hz (ISTS input signal).
Speech Test Material
Experimental testing was conducted in two different test scenarios, and the test material differed slightly between these conditions.
Restaurant Scenario: The speech test used for this test condition was a modified version of the American English Matrix Test (AEMT; Hörtech, 2014). Twenty sentences were employed for each test condition, unless there was not an observed convergence, in which case up to 30 sentences were administered. The intensity level of the sentences was presented adaptively, automatically controlled by the AEMT software. The recorded score for each individual test condition was the Speech Reception Threshold for 80% correct (SRT-80). That is, the SNR where the participant was repeating 80% of the words correctly. The background noise for this condition is explained below.
Party Scenario: A modified AEMT also was used for this test condition, using the conventional adaptive presentation method and scored for SRT-50. The background noise was the sentences of the AEMT, presented uncorrelated from 7 loudspeakers surrounding the participant.
Test Procedure.
The test procedure also differed between the two scenarios.
Restaurant Scenario: This test procedure was used to compare: Signia AX Augmented Focus “On” vs. “Off,” Signia AX to competitive models, and the HL group aided with Signia AX to the NH group. Participants were seated in the center of an audiometric test suite, surrounded by 8 loudspeakers. The loudspeakers were equally spaced at 45° azimuth intervals (e.g., 0°, 45°, 90°, 135°, etc.). The target sentences of the AEMT were presented from the loudspeaker directly in front of the participant (0° azimuth). Soft ambient sound was continuously presented from five of the surrounding speakers at a level of 45 dBA. A few seconds before the target sentence was delivered, recorded laughter of 76 dBA (simulating a sudden laughter burst) was presented randomly from one of the three loudspeakers behind the participant (135°, 180°, or 215°). After each sentence, there was a pause in the laughter, until it was again presented (from a different loudspeaker) to coincide with the next sentence. For the comparative hearing aid testing, conditions were counterbalanced, and participants were assigned to a specific ordering. A training session was conducted for both groups of participants.
Party Scenario: This environment only was used to compare the HL group aided with Signia AX to the NH group. This test condition used the same loudspeaker arrangement described for the Restaurant Scenario; a test design used in previous research (Powers & Fröhlich, 2014; Froehlich et al., 2015; Froehlich & Powers, 2015). The target sentences of the AEMT were presented from 0° azimuth. The competing signal was the AEMT sentences with between-sentence gaps removed, presented uncorrelated from the seven loudspeakers surrounding the listener. The resulting output of the competing sentences was 72 dBA at the position of the participant; binaural beamforming was activated. A speech babble was added to the competing material, presented at a level 15 dB below the sentences.
Restaurant Scenario results
Augmented Focus “On” versus “Off”: For this comparison, the effect of the Augmented Focus feature was isolated by testing with it on vs. off. The findings for this comparison are displayed in Figure 3. Observe this new feature had a large benefit for speech recognition, improving the SRT-80 by 3.9 dB SNR. This benefit was statistically significant according to a paired t-test (t(15) = 3.93, p < .01). The result shows how Augmented Focus adds further benefit to the performance of the conventional directional system which was active in the Augmented Focus “Off” setting.
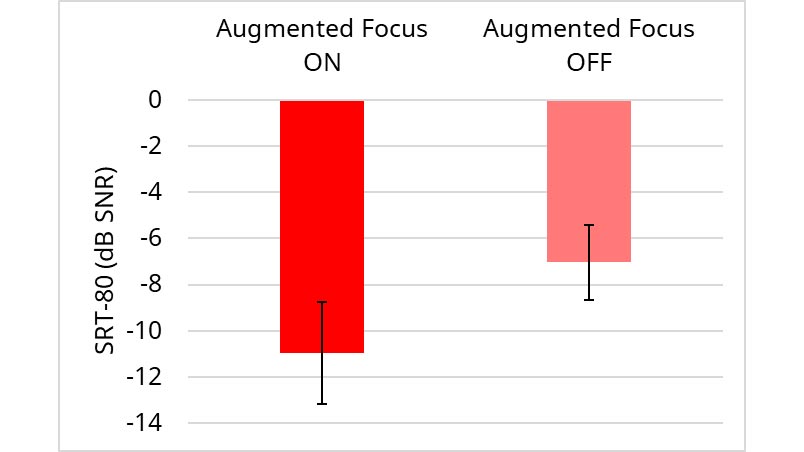
Figure 3. Mean AEMT scores (SRT-80) for the Augmented Focus feature “On” vs. “Off”. Testing conducted in the Restaurant Scenario. Error bars represent 95% confidence intervals.
Comparison to competitive products: With the Augmented Focus feature activated, the Signia AX was compared to two leading competitors, labeled Brand A and Brand B. The results of this testing are shown in Figure 4. The resulting mean SRT-80 for Signia AX was 2.1 dB superior to Brand A, and 7.3 dB superior to Brand B. Analysis of these data using paired t-tests with Bonferroni corrections for multiple comparisons showed that both differences were significant (t(15) = 2.72, p < .05; t(15) = 5.76, p < .001).
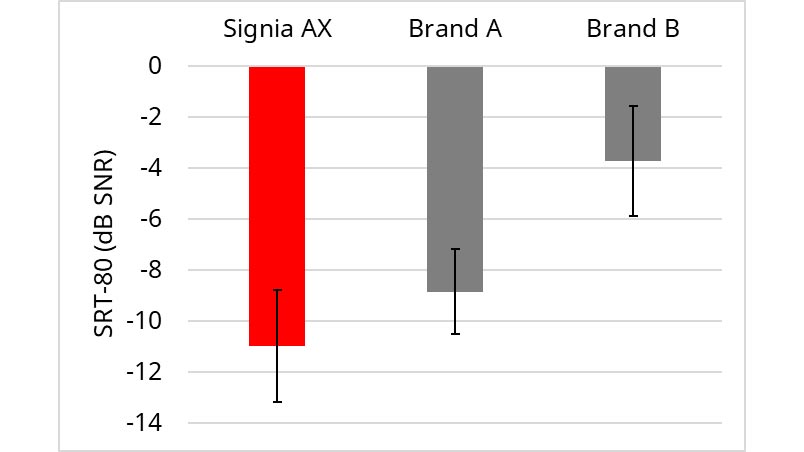
Figure 4. Mean AEMT scores (SRT-80) for the Signia AX, compared to two leading competitive products, labeled Brand A and Brand B. Testing conducted in the Restaurant Scenario. Error bars represent 95% confidence intervals.
HL group compared to NH group: In a final comparison using the Restaurant Scenario, we compared the performance of the HL group (aided with Signia AX) to the NH group. As shown in Figure 5, the findings for the two groups indicated equal performance with an observed mean difference of 0.1 dB. Analysis of these data using a t-test for independent samples showed no significant difference in mean SRT-80 between the groups (t(23) = 0.079, p = .94).
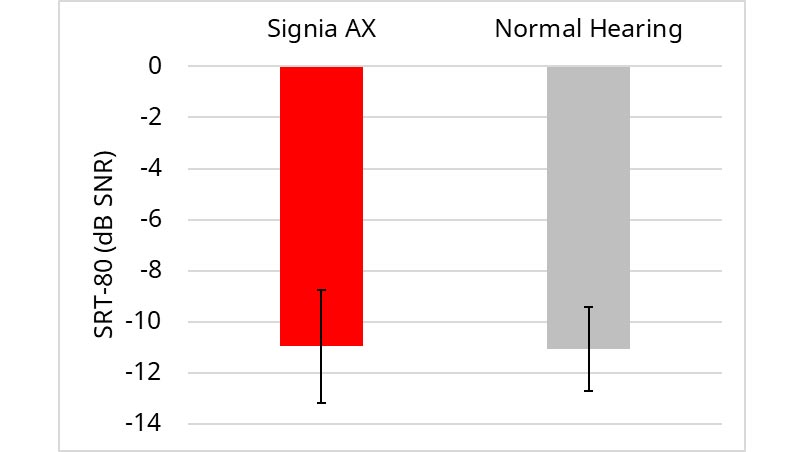
Figure 5. Mean AEMT scores (SRT-80) for the HL group aided with Signia AX, compared to the performance of the unaided NH group. Testing conducted in the Restaurant Scenario. Error bars represent 95% confidence intervals.
The resulting SRTs found in all these comparisons tend to be more negative (better) than those typically observed in previous research of this type. Recall, however, that the background noise was from the back, and these data are, therefore, consistent with the fact that hearing aids are very effective in reducing noise from the rear hemisphere. Additionally, the competing laughter was selected to simulate a typical real-world situation and was not designed or specially shaped to be an effective masker of speech. These factors, of course, do not impact the relative differences shown.
Party Scenario results
HL group (aided with Signia AX with binaural beamformer) compared to NH group: In 2015, Signia introduced full-audio device-to-device communication, which through binaural beamforming allowed for improved directivity. Research with this processing, at three different independent sites, revealed that when participants with hearing loss were aided, their speech-in-noise recognition was significantly better than their normal-hearing counterparts (Powers & Fröhlich, 2014; Froehlich et al., 2015; Froehlich & Powers, 2015). Given the changes to the digital platform since 2015, and the recent addition of the Augmented Focus feature, we wanted to confirm that the beamforming processing continued to allow wearers to perform better than people with normal hearing when the listening situation activated binaural beamforming, such as the Party Scenario used in this study.
The results of this testing are shown in Figure 6. Observe that a mean SRT-50 advantage of 2.1 dB SNR was present for the HL group. This benefit was statistically significant according to a t-test for independent samples (t(23) = 2.14, p < .05). Interestingly, this is very similar to the SNR advantage observed in the three previous studies mentioned. Observation of the individual SRTs showed 14 participants from the HL group (88%) performed better than the normal-hearing average SRT.
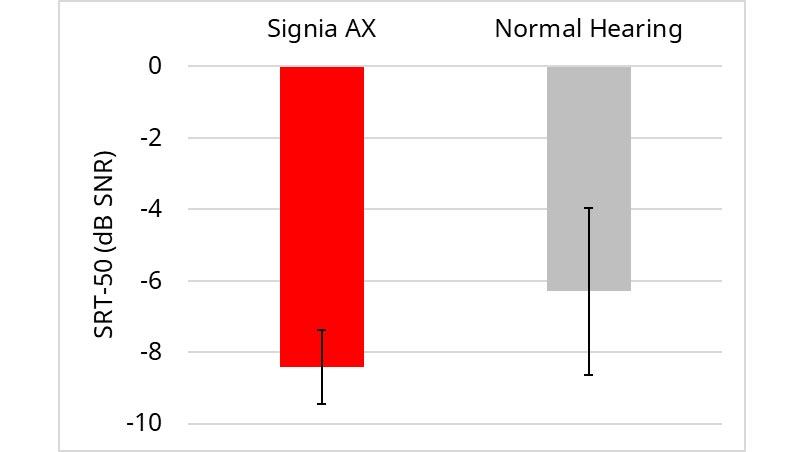
Figure 6. Mean AEMT scores (SRT-50) for the HL group aided with Signia AX, compared to the performance of the unaided NH group. Testing conducted in the Party Scenario. Error bars represent 95% confidence intervals.
Summary
Augmented Focus with its split processing adds benefits not offered by conventional single-stream processing and directionality. The Augmented Focus processing increases the contrast between focus and surroundings and makes the speech stand out as being clearer and easier to understand. This was supported by comparative measures of speech recognition in difficult listening situations, comparing results to the performance with single-stream processing and with competitor devices. In the fully automatic standard Universal program, performance with AX was on par with individuals with normal hearing, and when binaural beamforming was activated in a party scenario, AX wearers outperformed the normal hearing group. In general, based on the findings of this investigation, we conclude:
- For a restaurant scenario, the Signia AX Augmented Focus feature provides a significant advantage for speech understanding.
- When comparative speech recognition-in-noise measures are conducted, Signia AX performs significantly better than two leading competitors.
- In the standard Universal program, Signia AX wearers with hearing loss perform the same as their normal-hearing counterparts.
- For a party scenario, with activation of binaural beamforming, Signia AX wearers with hearing loss perform superior to their normal-hearing counterparts.
References
Best S., Serman M., Taylor B. & Høydal E.H. 2021. Augmented Focus. Signia Backgrounder. Retrieved from www.signia-library.com.
Chalupper J., Wu Y.-H. & Weber J. 2011. New algorithm automatically adjusts directional system for special situations. The Hearing Journal, 64(1), 26-28.
Froehlich M., Freels K. & Branda E. 2019. Dynamic Soundscape Processing: Research Supporting Patient Benefit. AudiologyOnline, Article 26217. Retrieved from http://www.audiologyonline.com.
Froehlich M., Freels K. & Powers T.A. 2015. Speech recognition benefit obtained from binaural beamforming hearing aids: Comparison to omnidirectional and individuals with normal hearing. AudiologyOnline, Article 14338. Retrieved from www.audiologyonline.com.
Froehlich M. & Powers T. 2015. Improving speech recognition in noise using binaural beamforming in ITC and CIC hearing aids. Hearing Review, 22, 12-22.
Hörtech 2014. International Matrix Tests: Reliable audiometry in noise.
Mueller H.G., Weber J. & Bellanova M. 2011. Clinical evaluation of a new hearing aid anti-cardioid directivity pattern. International Journal of Audiology, 50(4), 249-254.
Picou E.M. 2020. MarkeTrak 10 (MT10) Survey Results Demonstrate High Satisfaction with and Benefits from Hearing Aids. Seminars in Hearing, 41(1), 21-36.
Powers T.A. & Fröhlich M. 2014. Clinical results with a new wireless binaural directional hearing system. Hearing Review, 21(11), 32-34.
Ricketts T.A., Hornsby B.W. & Johnson E.E. 2005. Adaptive directional benefit in the near field: Competing sound angle and level effects. Seminars in Hearing, 26(2), 59-69.



